Rate limiting for distributed systems with Redis and Lua
How we use Redis and Lua to rate limit requests per second
August 28, 2018
Very early in building the telecom platform at CALLR, we needed to implement rate limiting for calls and API requests.
You probably know the story of lazy developers that fetch items on the API within a loop, for ∞. We also have call centers that use auto dialers badly configured ; they send too many calls per second (CPS). They think that the more “simultaneous” calls they send, the more calls they will “process”. Anyway, we implemented:
- Rate-limiting from upstream carriers and customers: calls above the limit are rejected,
- Rate-limiting to downstream carriers: calls above the limit are delayed (queued) or rejected if the wait is too long.
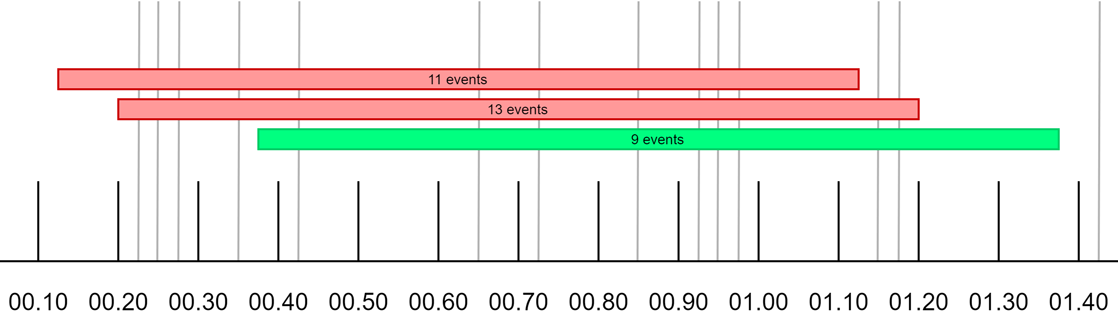
We needed to use a rolling time window of 1 second. The rolling window is an essential requirement, as it allows fair distribution over time, avoiding spikes every other second.
Given a limit of 10 calls per second, we do not want the user to be able to send 10 calls at 00:42:00.999 and 10 calls at 00:42:01.000. Using a rolling window, we make sure that the limit is respected at any given 1-second time window.
Here is another example:
Rolling time window illustrated
This illustration shows that it all depends on when you look back 1 second, and you cannot be more precise than a rolling window.
Our platform is distributed: calls are processed by a pool of servers. This means we cannot keep counters “locally”, we have to use “centralized” counters.
We chose Redis, with its powerful Lua scripting and clustering capabilities. Lua scripts run by Redis are extremely fast, and also atomic. Therefore they can safely be used by concurrent processes.
The implementation
For our needs, we implemented the token bucket and the leaky bucket algorithms in Redis scripts in Lua.
The token bucket algorithm in Redis and Lua
We use this algorithm when we simply want to reject calls that are above a given limit. We wrote 2 scripts:
- one script to add an event to a list of “token buckets”
- one script to get the current size (number of events) of a “token bucket”
A “bucket” has a pre-defined size (the number of calls per second we want to allow), and contains tokens (that represent events, like calls or API requests).
Here is the add script:
Quite simple right?
The script needs one argument: the timestamp of the event. It should be the Unix time with below-second precision. Like date +%s.%N : 1535457633.818637500. What ever format you choose, it is important that the values can be compared as numerics, because we use Redis sorted sets.
The script makes it easy to fill many buckets at a time: pass the buckets as Redis keys.
Every time we add an event to a bucket, we first remove the events that are past the current second with ZREMRANGEBYSCORE, to keep the sets small (more on that later).
Then we add the token with ZADD. Finally, we set an EXPIRE on each bucket we update, however that’s not mandatory. (We prefer self deleting keys to have a clean Redis keyspace.)
Redis sorted sets allow us to easily add and remove tokens based on time, with nanosecond precision.
ZREMRANGEBYSCORE does all the job, by clearing tokens that are below a certain “score”; in our case, 1 second in the past. Because we are using sub second precision, we keep a rolling window of 1 second in the bucket.
Let’s have an example. This is the bucket RT/CPS/OUT/PEER:45 at 1535458825.374375802:
pa2-rediscore42 ~ $ date +%s.%N && redis-cli ZRANGE RT/CPS/OUT/PEER:45 0 -1
1535458825.374375802
1) "1535458824.5664001"
2) "1535458824.6389999"
3) "1535458825.2572"
4) "1535458825.3072"
We have 4 events in the bucket. The oldest is at 1535458824.5664001 and the earliest is at 1535458825.3072. They are all within 1 second of 1535458825.374375802 (the current time).
Now, let’s have a look a few milliseconds later. The time is now 1535458825.632840728 (less than 1 second after our previous query):
pa2-rediscore42 ~ $ date +%s.%N && redis-cli ZRANGE RT/CPS/OUT/PEER:45 0 -1
1535458825.632840728
1) "1535458824.6389999"
2) "1535458825.2572"
3) "1535458825.3072"
4) "1535458825.4689"
5) "1535458825.5662999"
6) "1535458825.6162999"
We now have 6 events in the bucket. But did you notice that 1535458824.5664001 is gone? Of course it is! it’s more than 1 second away from the current time 1535458825.632840728. It was removed by ZREMRANGEBYSCORE. The oldest event is now at 1535458824.6389999, that’s still within 1 second of the current time.
To get the current size of a token bucket, this is the script:
As usual, the script needs the timestamp as a argument. Pass the bucket name as a key.
As you might have guessed, all we have to do is call ZREMRANGEBYSCORE to remove tokens older than 1 second in the past, and read the bucket size with ZCARD. This will give us the number of events in the past second.
Remember Redis scripts are atomic, which means that nothing can happen when one script is running.
You might wonder why we call ZREMRANGEBYSCORE in the add script. And you are right. This is not needed per se. An simpler implementation could ZADD when adding and ZREMRANGEBYSCORE+ZCARD when reading. But what would happen if you kept adding without ever reading? The bucket would grow indefinitely, and at some point, you would use all memory. That is why we remove old tokens when adding.
This is it for the token bucket! The usage is really simple: call the add script to fill buckets. Call the get script to read one bucket size.
The leaky bucket algorithm in Redis and Lua
The goal is to send calls to downstream carriers with a constant rate, with calls above the rate limit being queued (thus delayed), or rejected if the queue is too big.
The implementation is quite simple.
Let’s say that you want to respect 4 calls per second at a constant rate. Between each call, we must respect 1/4 second (250ms):
- 00:42:00.000
- 00:42:00.250
- 00:42:00.500
- 00:42:00.750
When we need to add an event to a leaky bucket, we “place it” at the next “slot” available with ZADD. Then we return the “offset”: the time we must wait in order to achieve a constant rate.
Here is the code.
As usual, the timestamp of the event is passed as an argument. This time, we also the need rate that needs to be respected (second argument).
The bucket is passed as a key.
Like the token bucket algorithm, every time we add an event we remove older tokens. Then, we fetch the last event in the queue with ZRANGE, and we add our own event at last + 1/rate.
In the end, we return the difference of time between the slot chosen, and the current time.
The application calling the script MUST respect the time to wait before actually doing the “event”!
Before running this script, we read the queue “length”, by reading the top item (ZRANGE KEY -1 -1) and comparing with the current time. If the queue is too big, meaning the wait is too long, we reject the call (actually we might send this call to another carrier).
This is it!
Gists
The scripts are available as gist here:
We’ve been using them for about two years, and it has been working great, even with tens of thousands of events per second.
Let us know what you think!
Other solutions
- Basic Rate Limiting from Redis Labs: very basic. Might be enough if you need to limit per minute or per hour. No rolling window.
- Redis-cell: a redis module that provides rate limiting using a GCRA algorithm. Best suited for HTTP requets with “per minute”/“per hour” limits.
- Better rate limiting with Redis sorted sets: very well explained. Javascript implementation using MULTI. Inspiration for our implementation in Lua.